Automatic Subtitles Thanks to SODA
27 Apr 2023This blogpost explains how a quick but working solution was built to automatically generate subtitles and transcripts from audio and video files. As a bonus, a simple web interface is available for non tech-savvy users. The source code of the project can be found on github.com/scumjr/highball. Cheers!
In the context of user research, a friend of mine regularly conducts video interviews. The recordings are replayed over and over in order to analyze the answers to a set of questions.
The recordings are quite long (usually between 45 min and 1h30) and the process is manual and tedious. She looked for a service to produce transcripts of these recordings but didn’t find an offer that fulfilled her needs. Indeed, interviews are conducted in non-English languages (eg. German, French) and most services either don’t handle them or produce low quality transcripts. Additionally, most services are hosted in the cloud, which means that interview files are probably shared with 3rd parties.
State of the Art
Speech recognition is an active research topic. While free and open-source solutions exist, most of them require large storage and CPU resources to use or train them. Few high quality and free open datasets exist, especially for non-English languages.
I spent a few hours trying to install and use some projects from Wikipedia’s list of speech recognition software (Kaldi, Common Voice, VOSK and DeepSpeech) without any success. The main reasons are either the lack of knowledge regarding some components (eg. TensorFlow) or no support/dataset for non-English languages.
I’ve no doubt that with enough time one of these projects can achieve great results, but I eventually went another way.
Google Live Caption
Google announced several times Live Caption, “an automatic captioning system that is fast and small enough to fit on a smartphone”. It notably works offline and supports a bunch of languages (English, French, German, Italian, Japanese and Spanish).
The goal of this project will be to make this library work outside of Chromium in order to produce subtitles.
The idea of making this library standalone isn’t new: 3 years ago, biemster shown on Hackaday how to use libsoda to write out a live transcription from an audio stream and the code is public: gasr. Marek Speech Recognition is a Rust project to allow easy usage of Speech Recognition libraries with a common API.
Retrieving libsoda.so
While publicly advertised by Google, Google Live Caption does not seem to be enabled anymore in Chrome or Chromium for unknown reasons, as mentioned in this commit message:
All of these changes are gated behind the kLiveCaptionMultiLanguage flag.
Anyway, the following command line enables the feature:
$ chromium --enable-features=LiveCaptionMultiLanguage --live-caption-multi-language
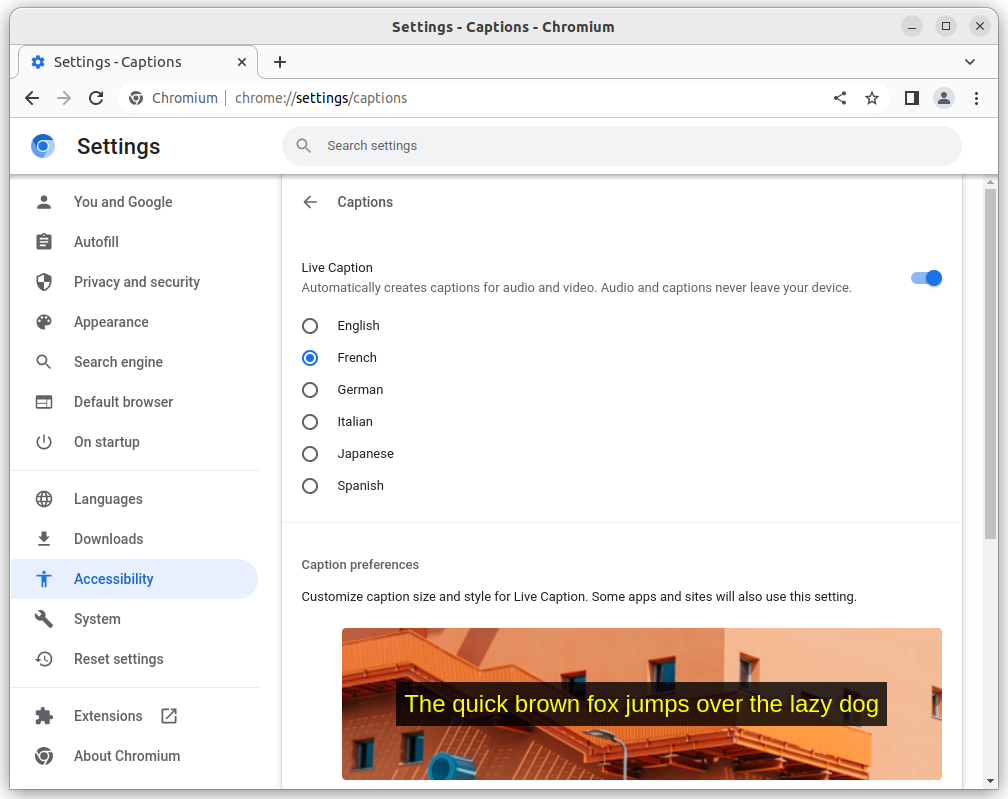
It leads to the download of several files (SODA means Speech On-Device API):
$ find ~/snap/chromium/ -iname '*soda*'
/home/user/snap/chromium/common/chromium/SODA
/home/user/snap/chromium/common/chromium/SODA/1.1.1.2/SODAFiles
/home/user/snap/chromium/common/chromium/SODA/1.1.1.2/SODAFiles/libsoda.so
/home/user/snap/chromium/common/chromium/SODALanguagePacks
/home/user/snap/chromium/common/chromium/SODALanguagePacks/en-US/1.0.2/SODAModels
/home/user/snap/chromium/common/chromium/SODALanguagePacks/en-US/1.0.2/SODAModels/SODA_punctuation_model.tflite
...
Bypassing Protections
Left as an exercise to the reader.
Making Use of libsoda.so
The library configuration (channel count, sample rate, language pack directory, etc.) is done through a Protobuf message.
Once initialized, the audio stream can be fed to the library at the specified sample rate. The recognition results are passed to a callback which writes to stdout each word along its timestamp. That’s it!
- Convert the media file into
.wav:
$ ffmpeg -i file.mp3 -ar 44100 file.wav
- Pipe it to soda to produce a
.jsonfile being a list of each word along its timestamp:
$ sox file.wav -c 1 -ts16 - | ./highball >file.json
- Wait until the whole media has been streamed to
highball…
$ head -9 file.json
[
[7620, "Comment"],
[8040, "faire"],
[8400, "pour"],
[8580, "être"],
[8880, "invisible"],
[10800, "dans"],
[11400, "la"],
[11520, "vie?"],
The transcription process works in real time which implies that the amount of time taken by the process is roughly the audio length.
From Timestamps to Subtitles
Converting the .json file to a .srt file is eventually done using a simple Python script:
$ ./subtitles.py --format srt file.json >file.srt
$ head -16 file.srt
WEBVTT
1
00:00:07.620 --> 00:00:10.700
Comment faire pour être invisible
2
00:00:10.800 --> 00:00:11.900
dans la vie ?
Des fois ?
3
00:00:12.000 --> 00:00:15.740
C'est important d'être vu comme par exemple
quand on parle à une foule.
Basically, the script breaks sentences given an arbitrary threshold of 900ms of silence. Additionally, lines are split on punctuation marks and a few rules are applied (eg. no more than 2 lines, max 38 words per line) to make subtitles more readable.
Web Interface
I eventually developed a basic web interface (thanks to Flask and bootstrap) to make the project a bit more user-friendly.
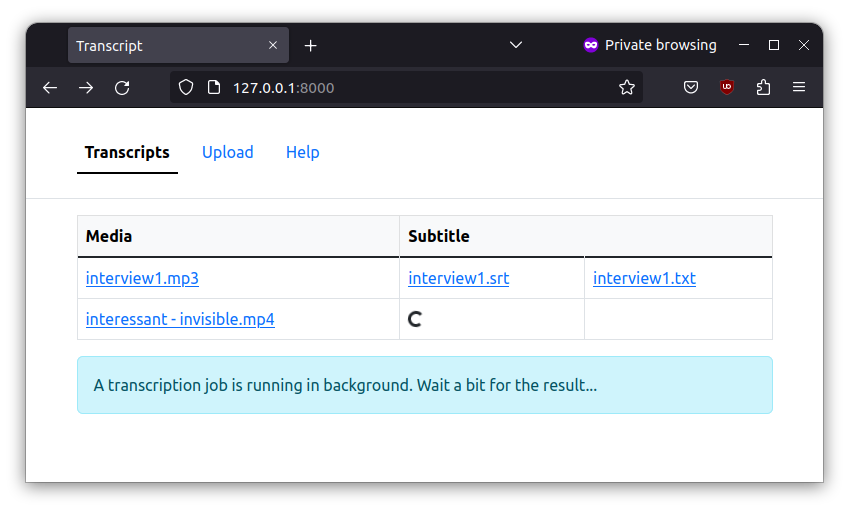
Last Words
This project is a quick and dirty solution to automatically generate subtitles and transcripts from audio and video files. There is still room for improvement:
- SODA works in real time. I wonder if the library could be used differently to speed up the transcription process (and potentially improve the result).
- The subtitles script is really basic. I guess it could be improved to split sentences in a better way.
- According to the Protobuf file, a speaker change detection feature is available but I didn’t find how to make it work.
Anyway, the results are pretty amazing for less than 500 lines of code!
$ wc -l highball/src/*.c highball/subtitles.py
195 highball/src/highball.c
43 highball/src/patch.c
122 highball/subtitles.py
360 total
To no one’s surprise, the hard work of speech recognition is done by Google Live Caption, which is a fantastic project.